La détection des éléments d'une facture (InvoiceNest)
- Julien Duval
- Python , Data
- 31 octobre 2025
Sommaire
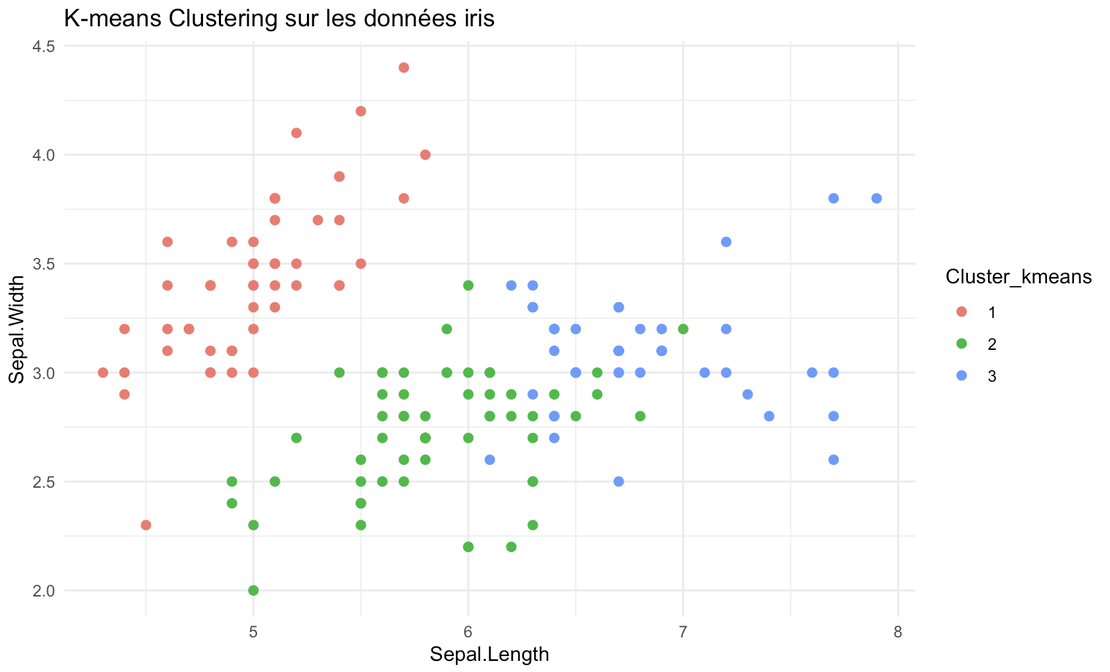
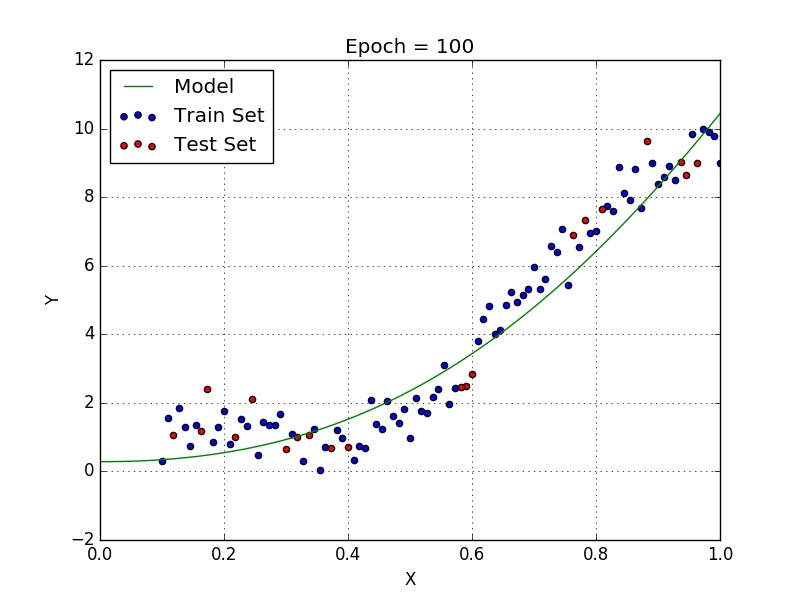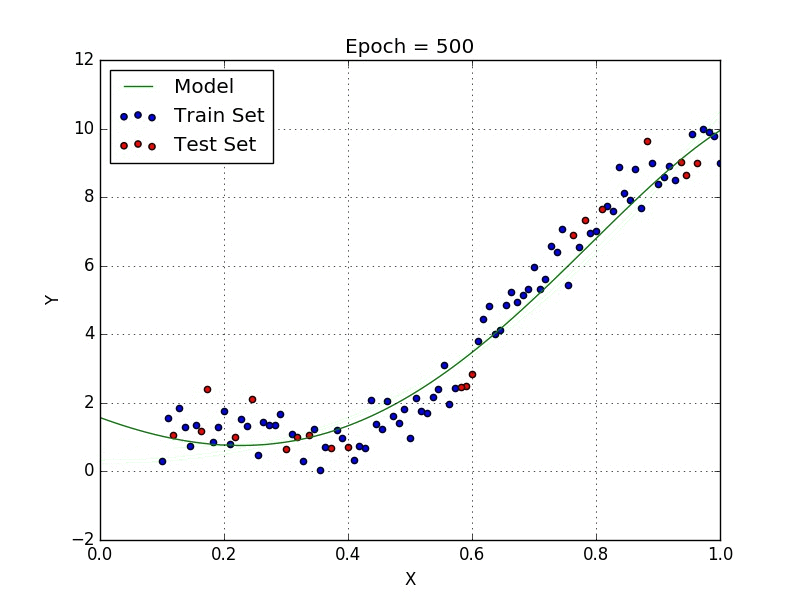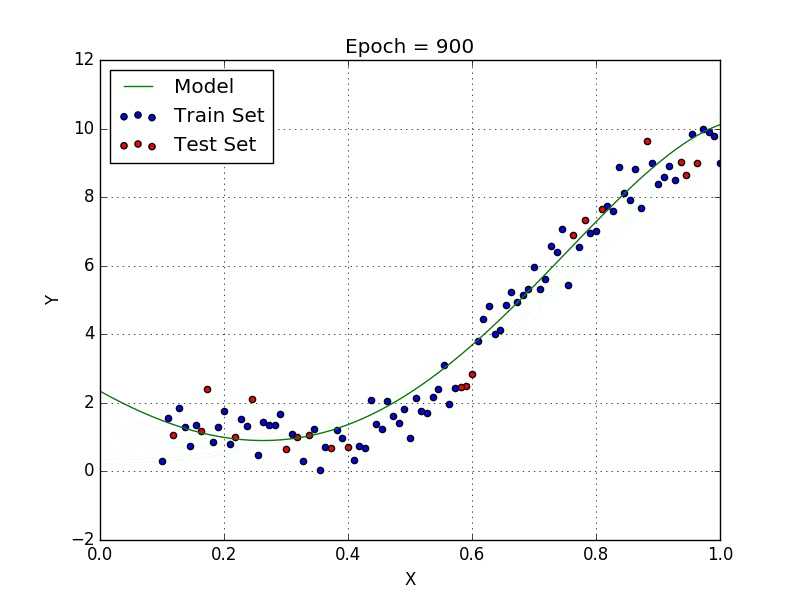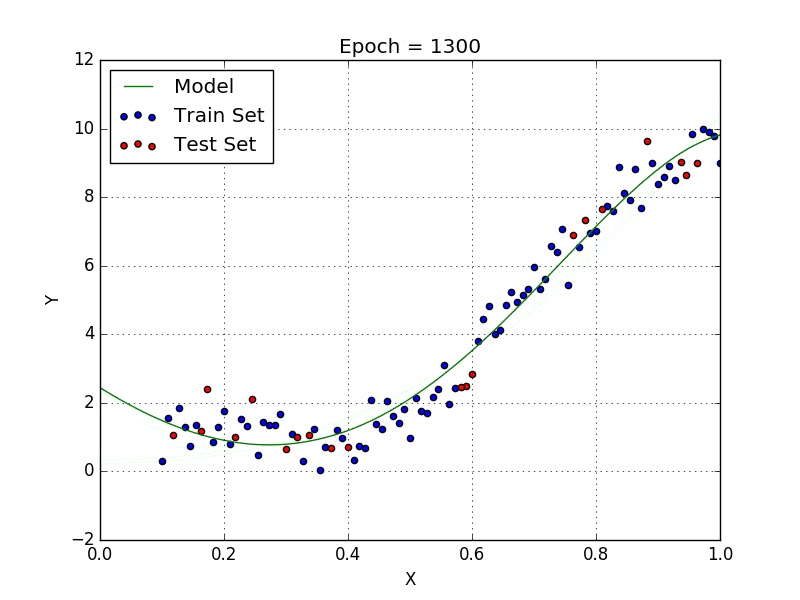
Le but de ce projet est de voir comment, à partir d’un dictionnaire de labels, des coordonnées des mots et d’une base de donnée d’annotations, nous pouvons extraire les données d’une facture
Aller au repo Git🧾 InvoiceReader — Module d’extraction de texte intelligent pour factures
Sous-projet du projet global (InvoiceNest)
🧠 Présentation générale
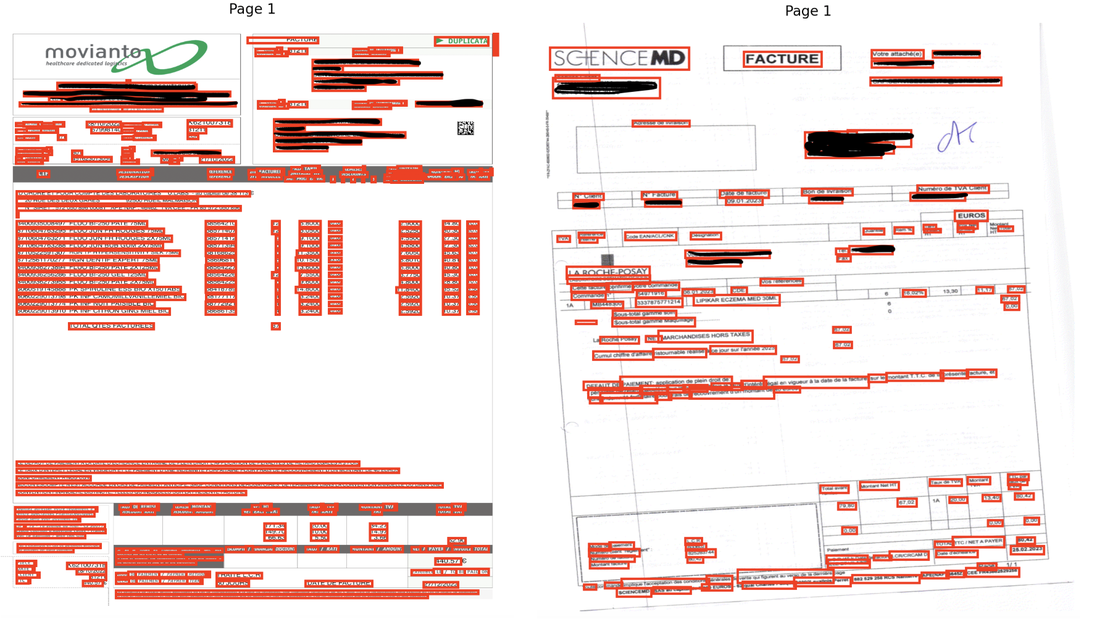
InvoiceReader est une solution d’extraction de texte depuis des factures PDF (natives ou scannées), développée dans le cadre d’un projet industriel à l’École des Mines de Saint-Étienne.Ce module constitue le premier maillon du projet InvoiceNest, dont l’objectif final est l’automatisation complète de la vérification de factures à l’aide de techniques de data science et machine learning.
Info
🧩 Objectif principal :
Transformer automatiquement une facture PDF en un fichier JSON structuré contenant :
- Le texte extrait (mots ou paragraphes)
- Les coordonnées de chaque élément (bounding boxes)
- Le taux de confiance associé à la lecture
🏗️ Contexte du projet
La genèse du projet découle :
- d’échanges avec des professionnels de la pharmacie,
- d’expériences de stages en entreprises,
- et de constats récurrents sur la perte de temps liée à la vérification manuelle des factures.
Le projet InvoiceNest ambitionne de relier automatiquement les factures fournisseurs avec les bons de commande, en détectant les incohérences et en facilitant la comptabilité.
Pour atteindre cet objectif, plusieurs sous-modules sont développés :
- InvoiceReader → Extraction et structuration du texte brut (présent projet)
- Annotation Tool → Interface graphique d’étiquetage supervisé
- Detection Engine → Reconnaissance automatique de labels et valeurs (en ML)
- InvoiceNest SaaS → Service web de gestion et vérification de factures
⚙️ Architecture et fonctionnement
Le fonctionnement général du module se décompose en plusieurs étapes successives :
Étape 1 : Lecture du PDF
- Le fichier PDF est décomposé en pages.
- Chaque page est d’abord testée avec la librairie pdfminer.six (lecture native du texte et extractions des images).
- Si pdfminer échoue (notamment pour les factures scannées) → la page est convertie en image.
Étape 2 : OCR (Reconnaissance Optique de Caractères)
- Application d’un OCR (EasyOCR) sur les images obtenues.
- Extraction du texte, coordonnées (p1, p2, p3, p4) et score de confiance.
Étape 3 : Filtrage et post-traitement
- Assemblage des mots en phrases ou paragraphes cohérents.
- Rectification de symétries et normalisation des coordonnées.
- Application de seuils (thresholds) pour filtrer les lectures incertaines.
Étape 4 : Écriture JSON
Le résultat final est un fichier structured_output.json de la forme :
{
"metadata": {
"machine": "Mac_Julien",
"version_logiciel": "0.0.3",
"date": "2024-12-17",
"hour": "10:13:19",
"file_path": "/Users/XXX/Desktop/src/facture_34054159__31012023.pdf",
"page_dim": [
590.76,
841.68
],
"number_of_pages": 7
},
"data": {
"0": {
"mwf5839g": {
"coordinates": [
[
41.4,
37.82650000000001
],
[
190.26050000000004,
37.82650000000001
],
[
190.26050000000004,
47.68649999999991
],
[
41.4,
47.68649999999991
]
],
"text": "PHARMACIE DE LA XXXX",
"conf": 1.0
}
}
}
}
⚡ Parallélisation et performances
Afin d’améliorer l’efficacité, l’extraction est exécutée en parallèle sur 5 PDF simultanément.
Avantages :
- Traitement rapide d’un grand volume de factures
- Réutilisation d’instances (cache mémoire)
- Support CPU et GPU selon l’environnement
Commande d’exécution typique :
python3 main.py <path_to_pdfs> -p -n 5 -gpu
Points techniques :
- Gestion fine des conflits lecture/écriture
- Nettoyage mémoire via gc.collect()
- Compatibilité confirmée sous macOS et Linux (Anaconda / Conda Envs)
🧪 Résultats et limites techniques
✅ Points forts :
- Précision améliorée sur les PDF natifs
- Extraction hybride (OCR + pdfminer)
- Architecture modulaire et évolutive
- Exécution multi-processus stable
⚠️ Limites connues :
- La librairie “pdfminer.six” contient une aberation algorithmique sur les fichiers .bmp enregistrés (problème de dimension) ce qui a dû être corrigé.
- Lenteur sur certains environnements macOS (notamment du à la librairie matplotlib.pyplot qui n’efface pas bien les données avec un grand nombre d’affichage)
- Mémoire non optimale sur des lots de >100 factures
📂 Structure du dépôt
InvoiceReader/
│
├── __pycache__/
│
├── old_class/
│
├── temp/
│
├── boxPlot.py
├── filter_results_OCR.py
├── jsonParser.py
├── main.py
├── PDF_miner.py
├── pdf_preprocess.py
├── performOCR.py
│
├── README.md
├── LICENSE
└── requirements.txt
🧩 Installation et exécution
1. Installer les dépendances
pip install -r requirements.txt
2. Exécuter le programme
<path_to_pdfs> peut être un fichier pdf ou bien un dossier de fichiers pdf
python3 main.py <path_to_pdfs> -p -n 5 -gpu
Options disponibles :
- -p Active la possibilité de plot les résultats sur l’image de la page pdf
- -n Nombre de processus
- -gpu Force l’exécution sur GPU si disponible pour le traitement OCR
🚀 Perspectives d’évolution
- Amélioration de la robustesse de pdfminer.six pour les images internes
- Optimisation mémoire et GPU
- Déploiement sous forme de service SaaS (InvoiceNest Cloud)
- Intégration de l’outil d’annotation (Tkinter) pour labelliser automatiquement les zones de texte
- Détection automatique de correspondances facture ↔ bon de commande
- Extension vers la comptabilité autonome et la facturation électronique
🙌 Crédits et remerciements
Développeur :
- Julien DUVAL
- Cédric GIOANNI
Encadrement académique :
- Projet industriel — École des Mines de Saint-Étienne (2024–2025)